支持向量机
分隔超平面为$w^Tx + b$
常数b类似于回归里的$w_0$
因为w为超平面的法向量,其中设距离为$\gamma$,$x_i 到x_0$的距离为$\gamma$,其中$x_0$为在平面的点,x为要求距离的点,
x的向量为$x_0 + \gamma \frac{w}{||w||}$ ,其中$\frac{w}{||w||}$为向量w的的单位向量,又有$w^Tx_0 + b = 0$与$w^Tw = ||w||^2$
$x-x_0 = \gamma \frac{\vec{w}}{||w||}$ 两边乘以$w^T$得
$w^T(x-x_0)= \gamma \frac{w^Tw}{||w||}$
$w^T(x-x_0)= \gamma \frac{||w||^2}{||w||}$
$w^Tx + b=\gamma||w||$
所以计算点A到平面的距离:值为$\frac{|w^TA + b| }{||w||}$
当$y_i$为1,-1时,$\gamma = \frac{2}{||w||}$ $s.t. w^Tx+b >= 1$
所以求$\gamma$的最大值,就是求$\frac{1}{2}||w||^2$ $s.t. w^Tx+b >= 1$的最小值
用拉格朗日乘子法来把约束条件加到求解方程里
$L(w,\alpha,b)=\frac{1}{2}||w||^2 + \sum\limits_{i=1}^m\alpha^i(1-y_i(w^Tx_i+b)$
令$\theta(w)=\mathop{max}\limits_{a_{i} >=0}L(w.\alpha,b)$
$\mathop{min}\limits_{w,b}\theta(w)=\mathop{min}\limits_{w,b}\mathop{max}\limits_{a_i >=0}L(w,\alpha,b)=p^*$
用对偶性,最大和最小互换,但是有kkt条件需要满足,才能保证$p^=d^$
$\mathop{max}\limits_{\alpha_i>=0}\mathop{mim}\limits_{w,b}L(w,\alpha,b)=d^*$
kkt条件为
min(f(x)),
$s.t. \\h_j(x)=0,j=1,2,..,p \\
g_k(x) <=0,k=1,2,…,q \\
x\in X\subset R^n
$
需要满足
- $L(w,\alpha,b)$对x求导为0
- $h_i(x)=0$
- $\alpha * g_k(x) =0$
对w,或b求导得到
$\frac{\partial L}{\partial w}=0 得到 w= \sum\limits_{i=1}^n\alpha_iy_ix_i$
$\frac{\partial L}{\partial b} =0 得到 \sum\limits_{i=1}^n\alpha_iy_i=0$
把w带回L中得到,一个只有$\alpha$的方程,??为什么是减去
$\mathop{max}\limits_{\alpha}\sum\limits_{i=1}^n\alpha_i - \frac{1}{2}\sum\limits_{i,j=1}^{n}\alpha_i\alpha_jy_iy_jx_i^Tx_j$
$s.t. \alpha_i >=0,i=1,2,…n, \\
\sum\limits_{i=1}^n\alpha_iy_i=0$
SMO内容
$\alpha$的部分
将方程变形,乘以-1,变成一个最小的问题
$\mathop{min}\limits_{\alpha}\frac{1}{2}\sum\limits_{i=1}^{n}\sum\limits_{j=1}^n\alpha_i\alpha_jy_iy_jx_i^Tx_j -\sum\limits_{i=1}^n\alpha_i $
$s.t. \alpha_i >=0,i=1,2,…n, \\
\sum\limits_{i=1}^n\alpha_iy_i=0$
加入松弛变量C,保证可以有部分不是线性可分的,条件变为
$s.t. C>= \alpha_i >=0,i=1,2,…n, \\
\sum\limits_{i=1}^n\alpha_iy_i=0$
SMO为更新两个$\alpha$
则 $\alpha_1^{new}y_1 + \alpha_2^{new}y_2 = \alpha_1^{old}y_1 + \alpha_2^{old}y_2 = \zeta $
固定其他的值,只改变$\alpha_2^{new}的解$先确定它的上下限
$L<=\alpha_2^{new}<=H$
因为$C>=\alpha>=0$ 和$\alpha_1^{new}y_1 + \alpha_2^{new}y_2 = \alpha_1^{old}y_1 + \alpha_2^{old}y_2 = \zeta $
所以
当$y_1\ne y_2$时
$\alpha_1 - \alpha_2 = \zeta$
$\alpha_2 = \alpha_1 - \zeta$
得到
$C-\zeta>=\alpha_2 >= -\zeta$
结合$C>=\alpha>=0$,得到
$L=max(0,-\zeta),H=min(C,C-\zeta)$
同理,当$y_1=y_2$时,
$L=max(0,\zeta-C),H=min(C,\zeta)$
因此得到$\alpha_2^{new}$的上下界L和H为
$L=max(0,\alpha_2^{old}-\alpha_1^{old}),H=min(C,C+\alpha_2^{old} -\alpha_1^{old}),ify_1\ne y_2$
$L=max(0,\alpha_2^{old}+\alpha_1^{old}-C),H=min(C,\alpha_2^{old} +\alpha_1^{old}),ify_1= y_2$
固定除了$\alpha_1 \alpha_2的其他变量$
$w(\alpha_2) = \sum\limits_{i=1}^n\alpha_i - \frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{i=1}^ny_iy_jx_i^Tx_j\alpha_i\alpha_j$
将$\alpha_1 \alpha_2$提出来得到
$w(\alpha_2) = \alpha_1 + \alpha_2 - \frac{1}{2}\alpha_1^2x_1^Tx_1 - \frac{1}{2}\alpha_2^2x_2^Tx_2 - y_1y_2\alpha_1\alpha_2x_1^Tx_2 - y_1\alpha_1v_1 - y_2\alpha_2v_2 + constant$
其中
定义$f(x_i) = \sum\limits_{j=1}^n\alpha_jy_jx_i^Tx_j + b$
$v_i =\sum\limits_{j=3}^n\alpha_jy_jx_i^Tx_j = f(x_i) -\sum\limits_{j=1}^2\alpha_jy_jx_i^Tx_j- b $
之后找到$\alpha_1和\alpha_2的关系$
因为$\sum\limits_{i=1}^n\alpha_iy_i=0$,所以将除了$\alpha_1y_1,\alpha_2y_2$的其他项看做常数-B
$\alpha_1y_1 + \alpha_2y_2 = B$,等式乘以$y_1$得到
$\alpha_1 = \gamma - s\alpha_2$ $,其中\gamma为By_1,s为y_1y_2$
带入公式,并且进行偏导
$\frac{\partial W(\alpha_2)}{\partial\alpha_2}=-s +1 +\gamma sx_1^Tx_1 - \alpha_2 x_1^Tx_1 - \alpha_2 x_2^Tx_2 - \gamma sx_1^Tx_2 + 2\alpha_2x_1^Tx_2 + y_2v_1 - y_2v_2 = 0$
导入$s=y_1y_2$得到
$\alpha_2^{new} = \frac{y_2(y_2-y_1+y_1\gamma(x_1^\intercal x_1 - x_1^\intercal x_2)+ v_1 -v_2)}{x_1^\intercal x_1 + x_2^\intercal x_2-2x_1^\intercal x_2}$
令$E_i = f(x_i)-y_i$
$\eta=x_1^Tx_1 + x_2^Tx_2 - 2x_1^Tx_2$
$E_i$为误差项,$\eta$为学习速率
已知$\gamma= \alpha_1^{old} + s\alpha_2^{old}$,和
$v_j=\sum\limits_{i=3}^n\alpha_iy_ix_j^Tx_i = f(x_j) -\sum\limits_{i=1}^2\alpha_iy_ix_j^Tx_i- b $$
简化$\alpha_2^{new}$
$\alpha_2^{new}=\alpha_2^{old} +\frac{y_2(E_1-E_2)}{\eta}$
加上约束,最终得到的解为
$\alpha_2^{new,clipped}=\begin{cases}
H,& \mbox{if }a_2^{new} >H \\
a_2^{new},& \mbox{if }L<=a_2^{new}<=H \\
L,& \mbox{if }a_2^{new} <L
\end{cases}$
又因为
$\alpha_1^{old}=\gamma -s\alpha_2^{old}$
$\alpha_1^{new} = \gamma -s\gamma_2^{new,clipped}$
消去$\gamma$得到
$\alpha_1^{new} = \alpha_1^{old} + y_1y_2(\alpha_2^{old} - \alpha_2^{new,clipped})$
b的部分
根据$y_1(w^Tx_1 + b)=1$两边乘以$y_1$,得到
$w^Tx_i+b =y_1$,又因为$w= \sum\limits_{i=1}^n\alpha_iy_ix_i$,得到
$\sum\limits_{i=1}^n\alpha_iy_ix_ix_1 +b=y1$单独提出$\alpha_1,alpha_2$,得
$b_1^{new} = y_1 -\sum\limits_{i=3}^n\alpha_iy_ix_i^Tx_1 - \alpha_1^{new}y_1x_1^Tx_1 - \alpha_2^{new}y_2x_2^Tx_1$
其中前两项为
$y_1 -\sum\limits_{i=3}^n\alpha_iy_ix_i^Tx_1=-E_1 + \alpha_1^{old}y_1x_1^Tx_1 + \alpha_2^{old}y_2x_2^Tx_1 + b^{old}$
整理得到
$b_1^{new}=b^{old} -E_1-y_1(\alpha_1^{new}- \alpha_1^{old})x_1^Tx_1 -y_2(\alpha_2^{new}-\alpha_2^{old})x_2^Tx_1$
同理得到$b_2^{new}$
$b_2^{new}=b^{old} -E_2-y_1(\alpha_1^{new}- \alpha_1^{old})x_1^Tx_2 -y_2(\alpha_2^{new}-\alpha_2^{old})x_2^Tx_2$
当$b_1,b_2都有效时,b^{new}=b_1^{new} = b_2^{new}$
所以,b的取值为
SMO计算梳理
- 计算误差$E_i$
$E_i=f(x_i) - y_i = \sum\limits_{j=1}^n\alpha_jy_jx_i^Tx_j +b -y_i$
- 计算上下限
- 计算$\eta$
$\eta=x_1^Tx_1 + x_2^Tx_2 - 2x_1^Tx_2$
- 更新$\alpha_j$
$\alpha_j^{new}=\alpha_j^{old} +\frac{y_j(E_1-E_j)}{\eta}$
- 根据取值范围修剪$\alpha_j$
$\alpha_j^{new,clipped}=\begin{cases}
H,& \mbox{if }a_j^{new} >H \\
a_2^{new},& \mbox{if }L<=a_j^{new}<=H \\
L,& \mbox{if }a_j^{new} <L
\end{cases}$
- 更新$\alpha_i$
$alpha_i^{new} = \alpha_i^{old} + y_jy_i(\alpha_j^{old} - \alpha_j^{new,clipped})$
- 更新$b_i,b_j$
$b_i^{new}=b^{old} -E_i-y_i(\alpha_i^{new}- \alpha_i^{old})x_i^Tx_i -y_j(\alpha_j^{new}-\alpha_j^{old})x_j^Tx_i$
$b_j^{new}=b^{old} -E_j-y_i(\alpha_i^{new}- \alpha_i^{old})x_i^Tx_j -y_j(\alpha_j^{new}-\alpha_j^{old})x_j^Tx_j$
- 根据bi,bj更新b
1 | import numpy as np |
1 | data_arr,label_arr = loadDataset('../../Downloads/machinelearninginaction/Ch06/testSet.txt') |
100
1 | set(label_arr) |
{-1.0, 1.0}
1 | #流程为 |
1 | b,alphas = smo_simple(data_arr,label_arr,0.6,0.001,10) |
fullSet, iter: 0 , pairs changed 7
iteration number: 0
fullSet, iter: 0 , pairs changed 4
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 6
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 0
iteration number: 5
fullSet, iter: 5 , pairs changed 0
iteration number: 6
fullSet, iter: 6 , pairs changed 0
iteration number: 7
fullSet, iter: 7 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 0
iteration number: 5
fullSet, iter: 5 , pairs changed 0
iteration number: 6
fullSet, iter: 6 , pairs changed 0
iteration number: 7
fullSet, iter: 7 , pairs changed 0
iteration number: 8
fullSet, iter: 8 , pairs changed 0
iteration number: 9
fullSet, iter: 9 , pairs changed 0
iteration number: 10
1 | #边界上的样本对应的α_i=0或者α_i=C,在优化过程中很难变化,然而非边界样本0<α_i<C会随着对其他变量的优化会有大的变化 |
1 | data_arr, label_arr = loadDataset('../../Downloads/machinelearninginaction/Ch06/testSet.txt') |
1 | b, alphas = smoP(data_arr,label_arr,0.6,0.001,40) |
fullSet, iter: 0 , pairs changed 6
iteration number: 1
non-bound, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
$w = \sum\limits_{i=1}^m\alpha_iy_ix_i$
1 | #计算w值 |
1 | calc_ws(alphas,data_arr,label_arr) |
matrix([[ 0.65307162],
[-0.17196128]])
1 | calc_ws(alphas,data_arr,label_arr) |
matrix([[ 0.65307162],
[-0.17196128]])
1 | #绘制样本 |
1 | from matplotlib import pylab as plt |
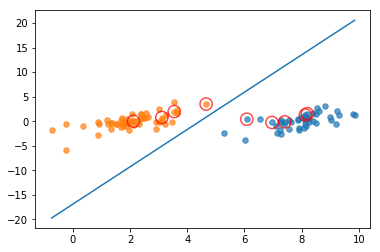
c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
1 | b, alphas = smo_simple(data_arr,label_arr,0.6,0.001,10) |
fullSet, iter: 0 , pairs changed 3
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 4
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 3
iteration number: 0
fullSet, iter: 0 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 4
iteration number: 0
fullSet, iter: 0 , pairs changed 3
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 3
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 2
iteration number: 0
fullSet, iter: 0 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 0
iteration number: 5
fullSet, iter: 5 , pairs changed 0
iteration number: 6
fullSet, iter: 6 , pairs changed 0
iteration number: 7
fullSet, iter: 7 , pairs changed 0
iteration number: 8
fullSet, iter: 8 , pairs changed 0
iteration number: 9
fullSet, iter: 9 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 0
iteration number: 5
fullSet, iter: 5 , pairs changed 0
iteration number: 6
fullSet, iter: 6 , pairs changed 1
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 3
iteration number: 0
fullSet, iter: 0 , pairs changed 0
iteration number: 1
fullSet, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 0
iteration number: 5
fullSet, iter: 5 , pairs changed 0
iteration number: 6
fullSet, iter: 6 , pairs changed 0
iteration number: 7
fullSet, iter: 7 , pairs changed 0
iteration number: 8
fullSet, iter: 8 , pairs changed 0
iteration number: 9
fullSet, iter: 9 , pairs changed 0
iteration number: 10
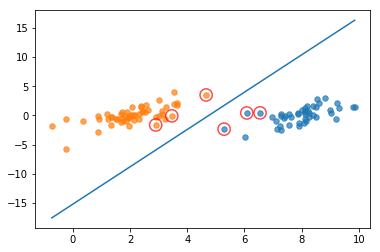
1 | b, alphas = smoP(data_arr,label_arr,0.6,0.001,40) |
fullSet, iter: 0 , pairs changed 6
iteration number: 1
non-bound, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
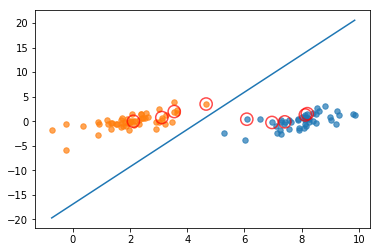
1 | b, alphas = smoP(data_arr,label_arr,0.01,0.001,40) |
fullSet, iter: 0 , pairs changed 10
iteration number: 1
non-bound, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
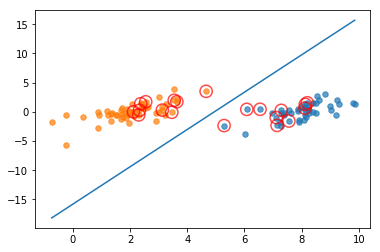
1 | b, alphas = smoP(data_arr,label_arr,55,0.001,40) |
fullSet, iter: 0 , pairs changed 8
iteration number: 1
non-bound, iter: 1 , pairs changed 0
iteration number: 2
fullSet, iter: 2 , pairs changed 0
iteration number: 3
核函数
径向基核函数
$k(x,y) = exp(\frac{-||x -y||^2}{2\sigma^2})$
自变量为向量,可以计算自变量相对于(0,0)或者其他的向量距离
$\sigma$为到达率(reach)或者函数值跌落到0的速度参数
1 | #转换核函数 |
1 | #修改用到核函数的辅助函数 |
$f(x) = \sum\limits_{i=1}^m\alpha_i^*y_iK(x\cdot x_i) + b^*$
1 | def testRbf(k1=1.3): |
1 | testRbf() |
fullSet, iter: 0 , pairs changed 30
iteration number: 1
non-bound, iter: 1 , pairs changed 5
iteration number: 2
non-bound, iter: 2 , pairs changed 2
iteration number: 3
non-bound, iter: 3 , pairs changed 0
iteration number: 4
fullSet, iter: 4 , pairs changed 0
iteration number: 5
there are 29 Support Vectors
the training error rate is: 0.130000
the test error rate is: 0.150000
$\sigma$ 如果太小,会得到很多支持向量,因为各支持向量的影响会变小,所以需要更多支持向量,但是容易过拟合
$\sigma $如果过大,则支持向量变小,容易欠拟合
手写识别问题回顾
1 | def img2vector(filename): |
1 | testDigits() |
fullSet, iter: 0 , pairs changed 104
iteration number: 1
non-bound, iter: 1 , pairs changed 11
iteration number: 2
non-bound, iter: 2 , pairs changed 0
iteration number: 3
fullSet, iter: 3 , pairs changed 0
iteration number: 4
there are 115 Support Vectors
the training error rate is: 0.000000
the test error rate is: 0.016129